 BI 系统中看似很冗余的快照表存在的意义
BI 系统中看似很冗余的快照表存在的意义
持续创作,加速成长!这是我参与「掘金日新计划 · 10 月更文挑战」的第17天,点击查看活动详情 (opens new window)
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA工作经验 一位上进心十足的【大数据领域博主】!😜😜😜 中国DBA联盟(ACDU)成员,目前从事DBA及程序编程 擅长主流数据Oracle、MySQL、PG 运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。 ✨ 如果有对【数据库】感兴趣的【小可爱】,欢迎关注【IT邦德】💞💞💞 ❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
摘要:观察一些大型用户的BI系统,经常会发现数据仓库中有很多快照表。如某交易业务的BI系统,交易明细表很大,被按月存储成多个分段表,为什么会有这么多看似很冗余的快照表存在呢?
观察一些大型用户的BI系统,经常会发现数据仓库中有很多快照表。如某交易业务的BI系统,交易明细表很大,被按月存储成多个分段表。还有一些相对不太大的表,计算时要和交易明细表关联,比如客户表、雇员表、商品表等等。每个月底,这些表的完整数据都会被存储成快照表,用于匹配当月的交易明细分段表。
为什么会有这么多BI 系统中
这个交易明细表就是常说的事实表,是用来存储发生事件的数据表,数据量会随着时间不断增长。除了交易明细表之外,订单表、保险单表、银行帐户存取记录表等也都是事实表。事实表中会有一些代码字段和其它表关联,比如上面说的交易明细表通过客户号、雇员号、商品号分别关联客户表、雇员表和商品表。再比如订单表通过产品号字段关联产品表、银行帐户存取记录表通过帐号字段关联帐户表等等。这些和事实表关联的表称为维表,下图中的交易明细表与客户表就构成了事实表和维表的关联关系:
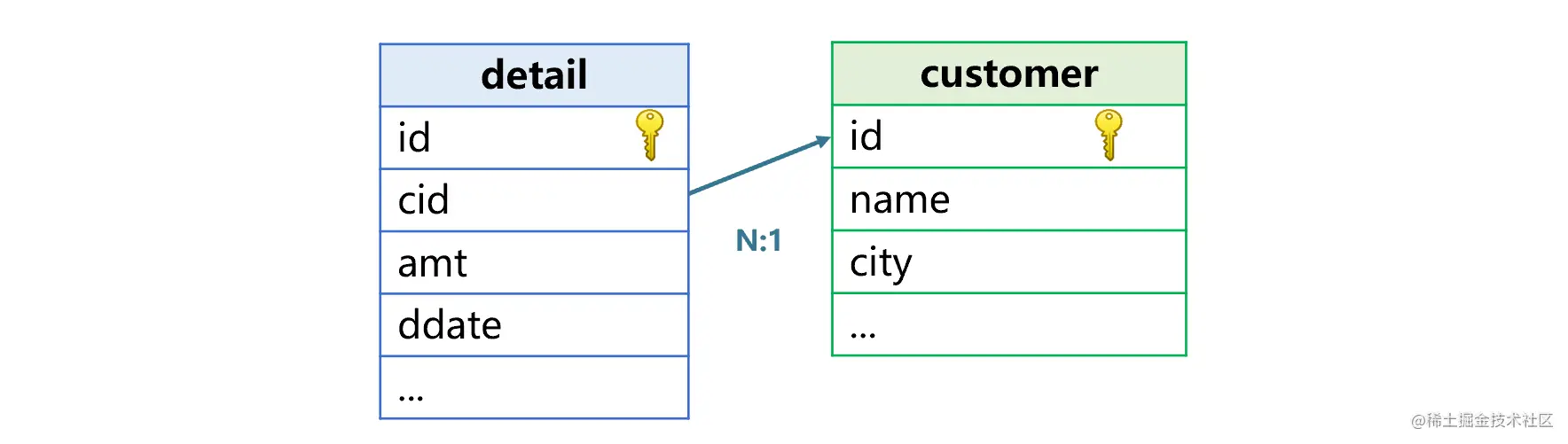
事实表关联维表的目的,是需要用维表的字段参与计算。例如交易明细表与客户表关联后,就可以按照客户所在城市来分组汇总交易金额、交易笔数等。
维表的数据相对比较固定,但仍然也会有修改。维表数据变动后,事实表中新产生的数据不受影响。而事实表以前的历史数据则可能和维表的新数据不匹配。这时,如果用事实表的老数据,去关联维表的新数据,就会出现错误的情况。
例如,编号为B20101的客户James,原先在纽约居住,产生了一些交易记录。到了2020年5月15日,James搬家到芝加哥,又产生了一些新的交易明细记录。如果我们直接将客户表中James的城市改成芝加哥,那么按照客户城市分组汇总交易金额时,James以前在纽约的交易也会被算到芝加哥,这明显是不对的。之所以出错,是因为James的交易记录到底算哪个城市和时间有关,一律算成纽约或者芝加哥都是不对的。
如果不对这个问题加以特别处理,就会导致BI系统中(针对历史数据)的统计值和ERP系统中(针对当时的数据)的统计值对不上的现象,而且这种错误还很难排查。
快照表就是为了解决这种问题而产生的。定时(比如每月末)生成有关数据表的快照,保存事实表某段时间(比如一个月)的数据和维表当时的完整数据,供后续统计分析计算,这样就会保证事实表总是和同期的维表关联,统计结果就不会出错了。
但是,这就会造成很多冗余的维表数据,增加数据库的存储量;维表通常还会有多个,每个维表又有多个快照表,会导致表间关系变得异常复杂,大大增加系统的复杂度。
这样,还会导致计算代码也随之变得复杂。比如说,每个月都有一个交易明细表及其对应的一批维表快照,如果要统计一年中按客户所在城市分组的交易金额和笔数,就要将十二个月的交易明细表和各自的维表快照关联后,再做十一次UNION。这还仅仅是简单的分组汇总,再复杂一些的统计分析计算,会出现非常长且复杂的SQL语句。维护都很困难,更不用说性能调优了。为此,很多采用快照方案的BI系统都禁止较长时间范围的统计分析计算,严重时只能选择一个时间周期(一个月)的数据做计算。
而且,快照方案也没有彻底解决维表变动带来的查询不准确问题。BI系统不可能在维度发生变动时就立即生成一个快照(那样会有太多的快照而造成巨大的存储量),一般只会定期生成快照表。这样,两次生成快照的时间点之间,如果发生维表数据的变动,仍然会出现计算错误。假设每个月最后一天生成交易明细表和客户表的快照。James是5月15日搬家的,在5月31日生成快照的时候,James的城市会被保存为芝加哥。而6月1日之后就要基于这个快照做5月的查询统计,那么5月1日到15日这段时间James的交易本来应该算纽约的,现在也都算成芝加哥的了,还是会出现错误,只是错误量相对较小而已。
还有一种变通办法是用事实表和维表生成宽表。将交易明细表和客户表数据关联好,生成交易宽表,这个宽表中的客户姓名、城市等就不会受到客户维表数据变动的影响了,并且能保证系统的数据结构相对简单。但是,宽表通常仍然只能是定期生成(实时生成宽表记录会拖累交易系统的性能),也就仍然会有上述的在两个生成时间点之间发生维表变化后导致的错误。而且,由于事实表和维表是多对一关系,交易宽表中的客户数据将出现大量冗余,造成事实表膨胀,空间占用会远远超过快照方案。再者,宽表结构维护很不灵活,特别是需要增加字段时还要考虑大量历史数据的处理。这就要求建立宽表时尽量将字段添加完全,而大而全的宽表占用的空间会更大。
其实,维表数据虽然有变动,但会相对很少,变动量与总数据量相比通常会少一个到几个数量级。利用这个特征,我们可以设计更低成本的方法来解决这个问题。
开源数据计算引擎SPL提供的时间键机制,就利用了这个特征,可以便捷、准确地解决维表数据变动问题。
具体的做法是,在维表中增加一个时间字段,和原有主键一起组成联合主键,这个字段称为时间键。事实表和维表关联时,用原来的外键字段加上合适的时间字段,与新维表的联合主键关联。时间键的关联方式和原来的外键有所不同,并不是用“相等”的关系判断的,而是找“指定时间前的最新记录”来关联。
仍以上述交易明细表和客户表为例,后者要增加一个生效时间字段edate,如下图:
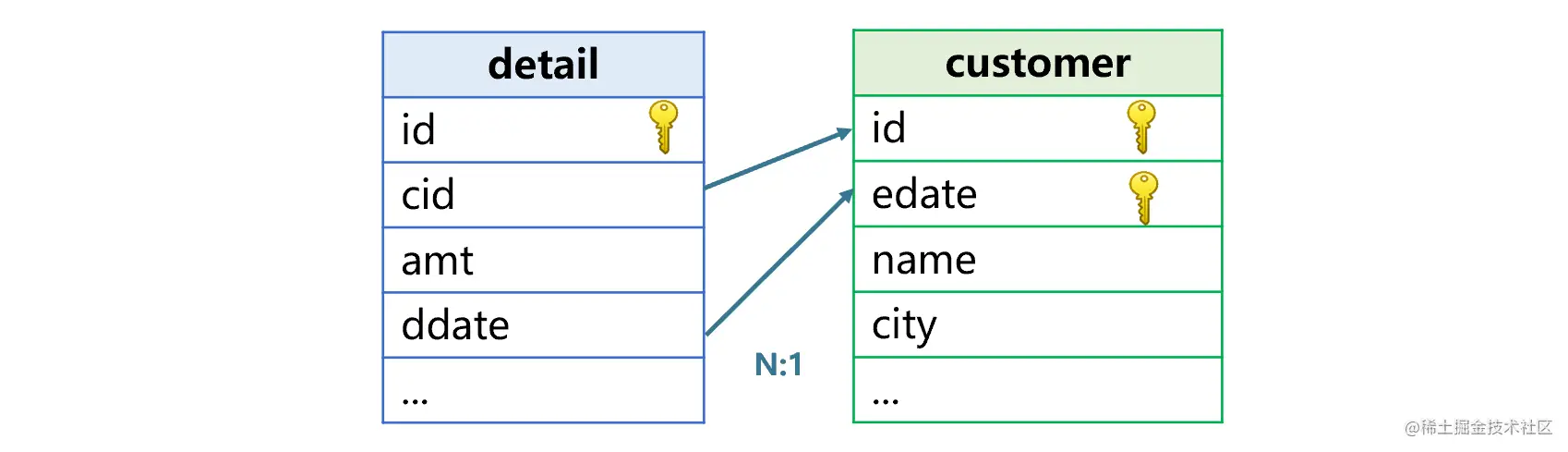
edate存储的是这条记录是什么时候生效的,也就是维表发生变动的时间。比如客户James搬家后,客户表就会变成下图这样:
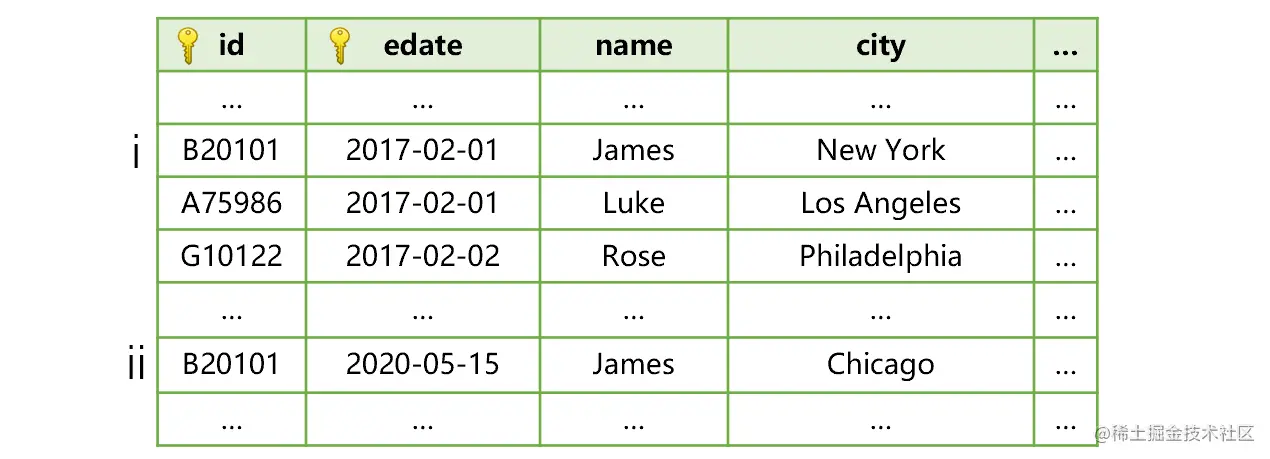
图中,客户James搬家前只有一条维表记录i。而搬家当天新增了第ii条记录,生效日期是搬家的时间2020-05-15。
这时,SPL做交易明细表和客户表关联,除了比较cid和id 是否相等,还要比较交易时间ddate和客户记录生效时间edate,找到edate不大于ddate的最大值,其所在记录才是对应的关联记录(也就是这个时间点之前的最新记录)。这样,James搬家前的交易记录日期是早于2020-05-15的,会和客户表中生效日期为2017-02-01的记录i关联,所以这些交易明细会被算作纽约的。而James搬家后的交易记录日期等于或晚于2020-05-15,就会和客户表中生效日期为2020-05-15的记录ii关联,这些交易明细就会被算作是芝加哥的。
可以看到,采用时间键机制后的关联结果是符合实际情况的。这是因为,我们是在维表发生数据变动的当时,增加维表记录并存入生效时间,所以可以保证后续计算的正确性。这样,就可以避免定期生成快照或者宽表时存在的问题,不会出现两次生成时间点之间的计算错误现象。
而且,因为维表的变动量很小,增加了变动信息的维表和原来的维表规模基本上是一样的,并不会大幅加大存储量。
理论上,也可以在关系数据库的维表中增加类似的时间字段,但是却没办法表示这种关联关系。时间键的关联显然不是常规的等值JOIN,使用非等值JOIN也要用复杂的子查询选出最新的维表记录再来关联,语句很复杂,也很难保证执行性能。所以,在关系数据库中,就只能用快照或宽表等方案来解决了。
SPL实现时间键机制的代码也很简单,大致是下面这样:
| A | B | |
|---|---|---|
| 1 | =T("customer.btx") | >A1.keys@t(id,edate) |
| 2 | =file("detail.ctx").open().cursor() | =A2.switch(cid:ddate,A1) |
| 3 | =B2.groups(cid.city;sum(amt),count(~)) |
A1读入客户表,B1定义联合主键id和edate,@s选项就表示主键的最后一个字段是时间键。如果业务需要,也可以用精度更高的日期时间类型字段作为时间键。
A2建立交易明细表的游标。
B2将游标和A1中的客户表关联起来,明细表的关联字段是cid和ddate,客户表是主键。使用方式和普通没有时间键的维表是一样的。
A3用关联的结果游标按照客户所在城市分组汇总交易金额和交易笔数,这时候就不必再关心时间键了。
SPL内置了时间键处理机制,运算性能和没有时间键的维表差别很小。关联时和普通维表一样,可以随意选定时间区间进行统计,不存在快照表那种难以跨越时间周期的问题。
SPL提供的时间键可以很简便地解决维表数据变动问题。事实表保持原状,只在维表中增加时间字段,并记录变动情况即可。可以在保证统计结果准确和计算性能的前提下,避免保留大量的快照表,降低系统复杂度;也可以避免宽表的大量数据冗余,保持灵活的系统结构。
作者:IT邦德 链接:https://juejin.cn/post/7159030892269142024 来源:稀土掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。