 Python常用模块 之 threading和Thread模块 第二阶段 线程通信及队列基操
Python常用模块 之 threading和Thread模块 第二阶段 线程通信及队列基操
# 1. 线程通信
# 1.1 互斥锁:
在多线程中 , 所有变量对于所有线程都是共享的 , 因此 , 线程之间共享数据最大的危险在于多个线程同时修改一个变量 , 那就乱套了 , 所以我们需要互斥锁 , 来锁住数据。
# 1.2 线程间全局变量的共享:
注意:
- 因为线程属于同一个进程,因此它们之间共享内存区域。因此全局变量是公共的。
# -*- coding: utf-8 -*-
"""
__author__ = 孤寒者
"""
import threading
a = 1
def func():
global a
a = 2
t = threading.Thread(target=func)
t.start()
t.join()
print(a)
复制代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 1.3 共享内存间存在竞争问题:
先来个正常的例子,不用多线程:
# -*- coding: utf-8 -*-
"""
__author__ = 孤寒者
"""
x = 0
n =1000000
def a(n):
global x
for i in range(n):
x += 1
def b(n):
global x
for i in range(n):
x -= 1
a(n)
b(n)
print(x)
复制代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
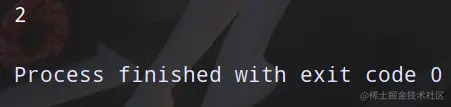
输出肯定和大家想的一样,毫无疑问是0!
# -*- coding: utf-8 -*-
"""
__author__ = 孤寒者
"""
from threading import Thread
x = 0
n =1000000
def a(n):
global x
for i in range(n):
x += 1
def b(n):
global x
for i in range(n):
x -= 1
if __name__ == '__main__':
a = Thread(target=a,args = (n,))
b = Thread(target=b,args = (n,))
a.start()
b.start()
# 一定要加阻塞,原因大家可以自己结合第一篇讲的自己好好想想哦~
a.join()
b.join()
print(x)
复制代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
提示:
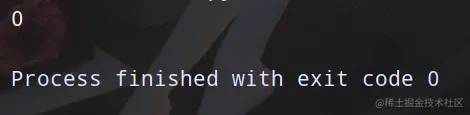
- 如果1000000不能出现效果可以继续在后面加0 你会发现这个结果千奇百怪!!!
# 1.4 使用锁来控制共享资源的访问:
下面引入互斥锁
- 在多线程中 , 所有变量对于所有线程都是共享的 ,因此 ,线程之间共享数据最大的危险在于多个线程同时修改一个变量 , 那就乱套了 , 所以我们需要互斥锁 , 来锁住数据。
- 只要我们操作全局变量的时候,就在操作之前加锁,在操作完之后解锁,就解决了这个资源竞争的问题!!!
第一种实现:
# -*- coding: utf-8 -*-
"""
__author__ = 孤寒者
"""
from threading import Thread, Lock
a = 0
n = 100000 # 指定加减次数
# 线程锁
lock = Lock()
def incr(n):
global a
# 对全局变量a做n次加1
for i in range(n):
lock.acquire()
a += 1
lock.release()
def decr(n):
global a
# 对全局变量a做n次减一
for i in range(n):
lock.acquire()
a -= 1
lock.release()
t_incr = Thread(target=incr, args=(n, ))
t_decr = Thread(target=decr, args=(n, ))
t_incr.start(); t_decr.start()
t_incr.join(); t_decr.join()
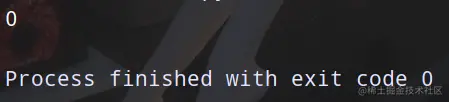
print(a)
复制代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# -*- coding: utf-8 -*-
"""
__author__ = 孤寒者
"""
from threading import Thread, Lock
a = 0
n = 100000 # 指定加减次数
# 线程锁
lock = Lock()
def incr(n):
global a
# 对全局变量a做n次加1
for i in range(n):
with lock:
a += 1
def decr(n):
global a
# 对全局变量a做n次减一
for i in range(n):
with lock:
a -= 1
t_incr = Thread(target=incr, args=(n, ))
t_decr = Thread(target=decr, args=(n, ))
t_incr.start(); t_decr.start()
t_incr.join(); t_decr.join()
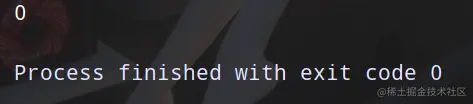
print(a)
复制代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 分析此阶段,我们会发现进程和线程的痛点!!!
- 下述参考本篇文章:《什么是协程》 (opens new window)后面出!
线程之间如何进行协作?
最典型的例子就是生产者/消费者模式:若干个生产者线程向队列中写入数据,若干个消费者线程从队列中消费数据。
(功能!)
1.定义了一个生产者类,一个消费者类。
2.生产者类循环100次,向同步队列当中插入数据。
3.消费者循环监听同步队列,当队列有数据时拉取数据。
4.如果队列满了(达到5个元素),生产者阻塞。
5.如果队列空了,消费者阻塞。
这里就引入了协程!是一种比线程更加轻量级的存在。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。
这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
代码走起来(依旧是生产者/消费者模式的例子!):
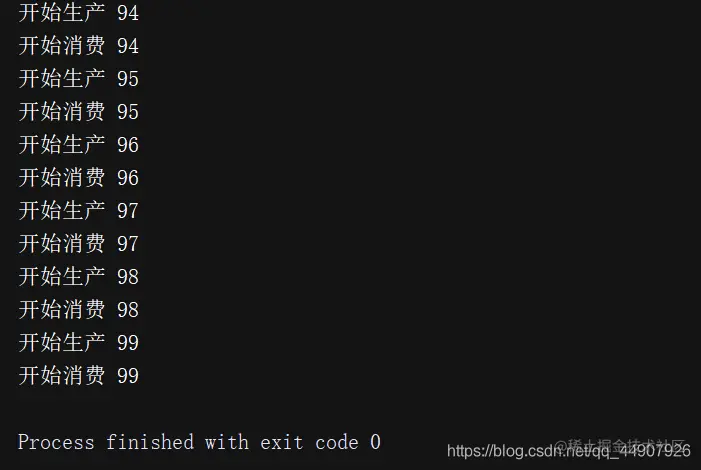
def consumer():
while True:
# consumer协程等待接收数据
number = yield
print('开始消费', number)
consumer_result = consumer()
# 让初始化状态的consumer协程先执行起来,在yield处停止
next(consumer_result)
for num in range(100):
print('开始生产', num)
# 发送数据给consumer协程
consumer_result.send(num)
代码中创建了一个叫做consumer_result的协程,并且在主线程中生产数据,协程中消费数据。
其中 yield 是python当中的语法。当协程执行到yield关键字时,会暂停在那一行,等到主线程调用send方法发送了数据,协程才会接到数据继续执行。
但是,yield让协程暂停,和线程的阻塞是有本质区别的。协程的暂停完全由程序控制,线程的阻塞状态是由操作系统内核来进行切换。
因此,协程的开销远远小于线程的开销!!!
复制代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
执行结果:
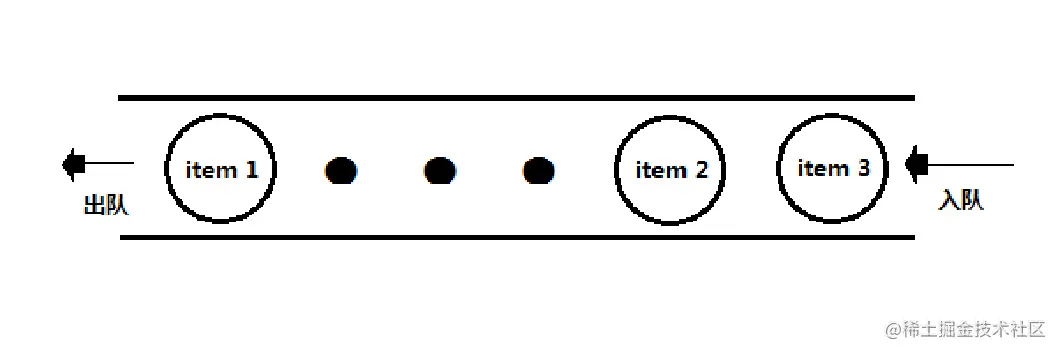
# 2. 队列的基本概念
- 一个入口,一个出口;
- 先入先出(FIFO)。
import queue
复制代码
1
2
2
队列操作一览:
- 入队: put(item)
- 出队: get()
- 测试空: empty()
- 测试满: full()
- 队列长度: qsize()
- 任务结束: task_done()
- 等待完成: join()
注意:
- get()等待任务完成,如果不加task_done()则不表示任务完成,只要加这句才表明完成。才会结束执行。
- join就是阻塞,直到这个任务完成(完成的标准就是每次取出都task_done()了)
简单使用队列的方法:
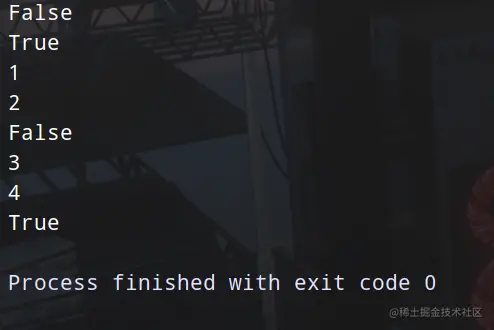
# -*- coding: utf-8 -*-
"""
__author__ = 孤寒者
"""
import queue
# 创建队列
q = queue.Queue(4)
# 入队
q.put(1)
q.put(2)
q.put(3)
print(q.full())
q.put(4)
print(q.full())
# 出队
print(q.get())
print(q.get())
print(q.empty())
print(q.get())
print(q.get())
print(q.empty())
复制代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 🔆In The End!
# 👑有关于Me
个人简介:我是一个硬件出身的计算机爱好者,喜欢program,源于热爱,乐于分享技术与所见所闻所感所得。文章涉及Python,C,单片机,HTML/CSS/JavaScript及算法,数据结构等。
从现在做起,坚持下去,一天进步一小点,不久的将来,你会感谢曾经努力的你!
认真仔细看完本文的小伙伴们,可以点赞收藏并评论出你们的读后感。并可关注本博主,在今后的日子里阅读更多技术文哦~
作者:孤寒者 链接:https://juejin.cn/post/7107896591079440391 来源:稀土掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
上次更新: 2023/04/05, 05:23:58