 使用scrapyd部署爬虫项目
使用scrapyd部署爬虫项目
# Scrapy爬虫项目部署
(scarpy是一个爬虫框架, 而scrapyd是一个网页版管理scrapy的工具, scrapy爬虫写好后,可以用命令行运行,但是如果能在网页上操作就比较方便. scrapyd就是为了解决这个问题,能够在网页端查看正在执行的任务,也能新建爬虫任务,和终止爬虫任务,功能比较强大.。要将spider部署到Scrapyd,可以使用由Scrapyd客户端包提供的Scrapyd -deploy工具。) 注意以下几个问题:
1、scrapy是什么? 一个爬虫框架,你可以创建一个scrapy项目
2、scrapyd是什么? 相当于一个组件,能够将scrapy项目进行远程部署,调度使用等
因此scrapyd可以看作一个cs(client-server)程序,因此毫无疑问我们需要安装和配置scrapyd(server)和连接的scrapy-client(client)。
# (1)实现项目部署前的准备(安装相关库)
1.scrapyd库的安装: 命令:pip install scrapyd
安装成功的现象:输入scrapyd,scrapyd带有一个最小的Web界面,启动后,通过访问http://localhost:6800。如下图: (opens new window)
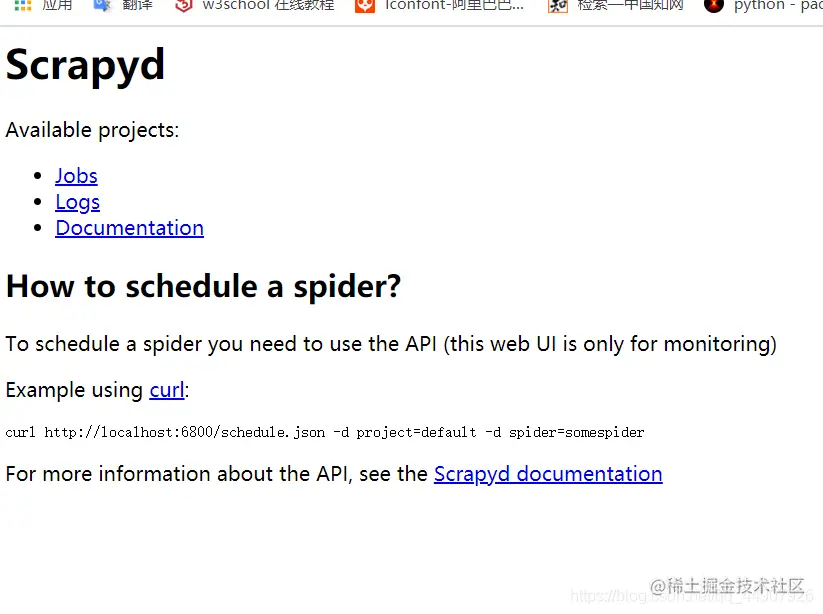
2.scrapyd-client库的安装: 命令:pip install scrapyd-client 安装成功现象:到scrapy项目下面 输入scrapyd-deploy 出现:Unknown target: default
# (2)修改scrapy.cfg文件:
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html
[deploy:spider55] #1.部署名称,可写可不写!
url = http://localhost:6800/ #2.url必须有,可以是远程服务器
project = douban #3.项目名称(不能删除)
username=cool #访问服务器所需的用户名和密码(可不写)
password=123456
复制代码
2
3
4
5
6
7
8
9
10
11
执行命令发现设置成功: 命令:scrapyd-deploy -l 作用:查看设置的部署名称和url

# (3)执行打包命令:(在有scrapy.cfg的目录下)
{部署操作会打包你当前项目。从返回的结果里面,可以看到部署的状态,项目名称,版本号和爬虫个数,以及当前主机名称。}
# 部署名称 项目名称
scrapyd-deploy spider55 -p douban
#效果:
'''
出现 {"node_name": "YNRBYA8RP4AT92A", "status": "ok", "project": "douban", "version": "1588083324", "spiders": 2}
'''
复制代码
2
3
4
5
6
7
8
# (4)启动爬虫:
#启动爬虫命令: 项目名称 爬虫名称
curl http://localhost:6800/schedule.json -d project=douban -d spider=db
#注意:启动爬虫之后一定要立马往数据库里写入起始url:
lpush db:start_urls https://movie.com/top250
#启动爬虫之后控制台输出:
{"node_name": "YNRBYA8RP4AT92A", "status": "ok", "jobid": "16903afa895b11ea886298fa9b72ce54"}
复制代码
2
3
4
5
6
7
8
9
10
现在就可以在网页中查看想要看到的一些日志信息等
scrapyd的web界面比较简单,主要用于监控,所有的调度工作全部依靠接口实现. 官方文档: scrapyd.readthedocs.io/en/latest/a… (opens new window)
# (5)关闭爬虫:
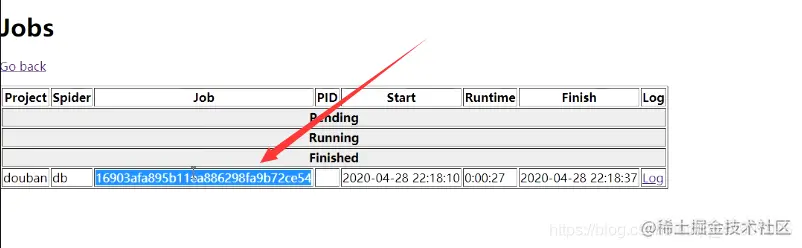
#关闭爬虫命令: 项目名称 在网页中的job里的job的id值,如下图:
curl http://localhost:6800/cancel.json -d project=douban -d job=4fc26e4209da11e9b344000c292b8398
复制代码
2
3
4
# 🔆In The End!
# 👑有关于Me
个人简介:我是一个硬件出身的计算机爱好者,喜欢program,源于热爱,乐于分享技术与所见所闻所感所得。文章涉及Python,C,单片机,HTML/CSS/JavaScript及算法,数据结构等。
从现在做起,坚持下去,一天进步一小点,不久的将来,你会感谢曾经努力的你!
认真仔细看完本文的小伙伴们,可以点赞收藏并评论出你们的读后感。并可关注本博主,在今后的日子里阅读更多技术文哦~
作者:孤寒者 链接:https://juejin.cn/post/7113703974770835493 来源:稀土掘金 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。